
Book Report on Software Estimation - Demystifying the Dark Arts
Estimation is something that I've done for a long time, but I've never really felt like I've done it well. I started rectifying that by reading Steve McConnell's Software Estimation: Demystifying the Black Art. The book is chock full of great ideas, and I've summarized them here for anyone looking to quickly improve their estimation skills.
Estimates vs. Targets vs. Commitments
The book starts off by talking about three things that often get confused:
- Commitments are dates that you have told external stakeholders that something will be ready. This is commonly a public launch.
- Targets are goals that you're trying to hit. They could be a feature that you're trying to launch by the end of the month, or it could be a metric that you're trying to move by some amount by the end of the quarter.
- Estimates are analytical statements about how long a team thinks it will take to deliver a set of functionality. These should be decoupled from commitments or targets.
We often confuse these things, and it results in missed opportunities for collaboration. Consider the case where a PM wants to give a live demo of a new feature at a conference next month. Engineering estimates the feature, and finds that it will take two months to deliver.
At this point, we should realize that we have two things: a target to deliver by the conference, and an estimate about how long the scoped work will take. The estimate suggests that the target will be difficult, so the team can take a few actions. The team can set a similar target with guardrails, they set a less ambitious target, or they could even keep the same target, but accept the risk that they may fail and have no demo. The one thing they shouldn't do is quibble over the underlying estimate unless there is a problem with the analysis.
Count, Compute, Judge
Once that difference is established, the book moves on to discuss how to produce accurate estimates. McConnell a three step process called count, compute, judge to do this.
The first step in count, compute, judge is to get an unbiased estimate of the size of your software by counting things related to its size. The things that you count will be dependent on your application, for UI applications it may be new screens, but backend applications may count new ETL jobs and new API endpoints, but it's important that you count something to get an unbiased read on the size of your project.
Once you've counted, the next step is to compute an estimate. For example, let's assume you're estimating a new feature. First you look at the mocks and you see that it will require 6 new screens, 3 new API endpoints, and updates to 2 API endpoints. You then look at historical data and see that it takes your team an average of 3 weeks to build a new UI screen, 2 weeks to create a new API endpoint, and 1 week to update an existing endpoint. This would mean that you estimate
6 * 3 + 3 * 2 + 2 * 1 = 25 total staff weeks.
This estimate is delightfully free of bias, but it can't account for the fact that each feature is unique. That's where the last step, judge, comes into play. You use judgement to tweak your initial counting and computations. In our case, you may notice the that API endpoints are in hairy parts of your code, so they will take longer than average. This may mean that we bump up our estimate of staff-weeks per API update to 2.5, giving us a new estimate of
6 * 3 + 3 * 2 + 2 * 2 = 27 total staff weeks.This estimate is still grounded in data, but now it's informed by judgement.
Estimating in Ranges
It can be easy to see this single value as The Estimate, but that would be flawed. Sometimes stuff goes way faster than we expect, more often it takes longer. Your estimates need to account for this variability by incorporating ranges.
The simplest way to do this is create a best case, a worst case, and expected case estimate complete with the underlying assumptions that created the estimate. Combining estimates and assumptions will give more accurate estimate and more tools to ensure a successful project.
Compare these two estimates
"The project will take 27 staff weeks"
vs.
"The project will take between 15 and 48 staff weeks, with an expected effort of 27 staff weeks. If we can find a lot of code re-use and the project gets fully-staffed we can save 2 and 3 weeks respectively. If the design mocks turn out to be really novel it could cost us up to 6 additional staff weeks."
The second estimate is more useful: it allows us to make informed engineering staffing decisions and shows us where we should can best focus our effort to derisk the project.
It's also worth noting that outcomes on projects aren't normally distributed, so they don't need to be symmetric around the expected value. In our example above, our best case was 12 staff-weeks lower than the expected case, but the worst case was 21 staff-weeks higher. That's okay. What matters is that you used the correct inputs into the estimation process.
The Cone of Uncertainty
Estimating in ranges is tightly tied to another key idea in the book: The Cone of Uncertainty.
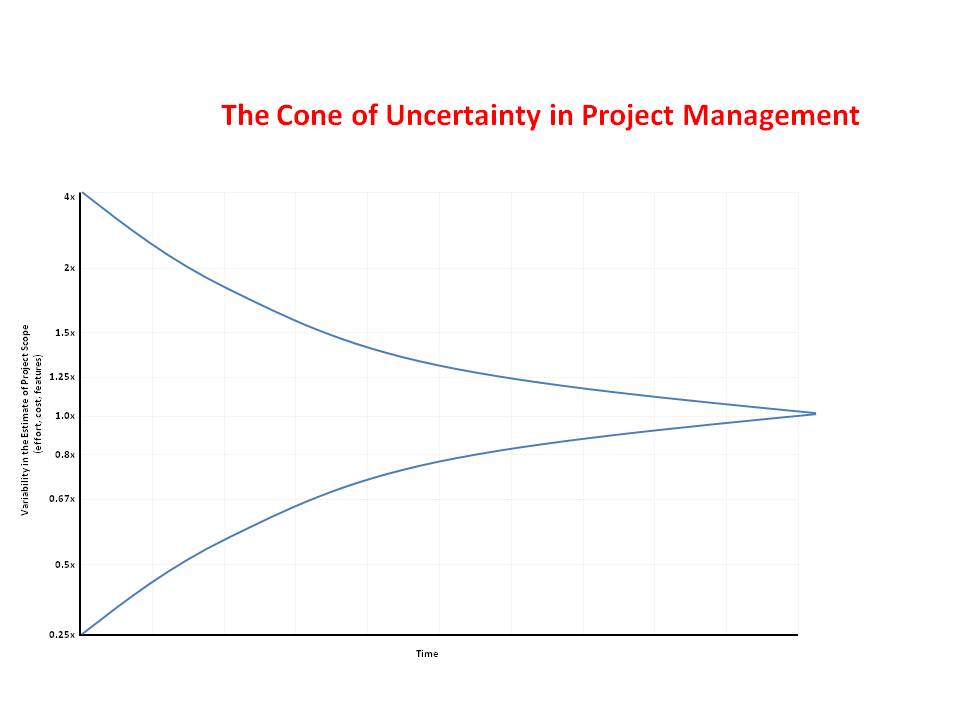
The cone is a visual representation of the fact that at the beginning of a project you have very little information, so you're very uncertain about how long it will take. As the project progresses you gain information and increased certainty until it is finally delivered. This has a couple of implications for estimates.
First, it means that at the beginning of a project you can probably only count very coarse grained things, so your best + worst cases may be quite different. These estimates will progressively narrow as you move down the cone.
This increasing clarity also means you'll want to use different estimation strategies depending on where you are in the project. In the beginning of the project you can really only count proxies for project size, so a quick and rough estimation technique like t-shirt sizing will do. As you get further on you can start to estimate individual tasks with more accurate estimates.
Communicating Accuracy in Estimates
The last point that comes up frequently is how to communicate the accuracy of estimates. Frequently your process of counting + computating will give numbers that seem very accurate but your estimation method couldn't have given you that degree of accuracy. For example, let's say that you're early in a project, you count the find that you have 23 components left to build and expect each one to take 7.25 staff days. That gives you 166.75 staff days of work.
That number seems very accurate, but much of the accuracy is a mirage. There is no way you can tell down to the quarter-of-a-day how long a 7+ month long project will take. If you present this estimate in its current form, they'll say "gee, it sounds like Maltz has really done his homework. He's working with 2 other engineers, so I should expect that in exactly 8 weeks."
This is not good. Slipping by 4-5 days on that estimate will seem like a miss, even though that's totally reasonable when you're at this stage. There are two easy techniques to avoid this.
- Remove significant digits. 166.75 Staff days reads different than 167 staff days, which is different still from 175 or 200 staff days. These differences in reported accuracy will help others calibrate their expectations.
- Change the units you estimate in. If you estimate down to the day, people will assume you're controlling the project down to the day. If your units are weeks, or months, people will assume less tight control. In our example above, changing 166.75 staff days may be better estimated as 33 staff-weeks or 7 staff months.
These ideas are the most common threads that run through Software Estimation: Demystifying the Dark Art, but there are many more. I found it to be brimming with strategies and tactics that immediately helped me become a better estimator. If you're trying to level up your own estimation skills I'd highly recommend picking it up.
A big thanks to Michael Stephens for reading an early draft of this post.Discussion, links, and tweets

Hey! Thanks for reading! If you like what you read and want more, you can follow me on Twitter.
Tweet Follow @maltzj